Introduction to Kubernetes: what problems does it solve?
Table of Contents

Nowadays Kubernetes is one of the most popular tool which is used to build large, distributed system in the cloud. Many companies decide to use it in their new projects or are migrating already existing one. Despite of that, if you still don’t know what Kubernetes is, this blog post is definitely for you.
Let’s imagine that we know use a time machine and go back in time to 2000s (to help you with that, try to remind what music band you’ve listened then or what clothes you’ve been wearing). We’re working in a big company, in a software development department. And we’ve got a new brilliant idea for an application.
So what do we do? Can we right away start coding, run application and show it to potential users? It depends on a project, but probably not. But why?
It would depend on a company, but in general it wasn’t a trivial task. Chiefly because in large organizations a software/hardware infrastructure was either not well organized or the process for requesting for software tools, servers, databases etc. was so long that it blocks new projects right from the start. Development teams instead of focusing on delivering a business value from day one, were forced to first answer to questions like: where and how to run database?, how to deploy an application on a server?, how to set up network traffic? and so on. Figuring out it could take months of waiting for infrastructure teams to resolve it.
Believe it or not, at that time many companies were struggling with that (some are also struggling even today). One company in particular was really feeling a pain of it, when they tried to build a new product in couple on months, but ended up exceeding the deadline. The company was called Amazon.
Like any other companies in early 2000s, Amazon was trying to find a way how to bust productivity of their software development teams. And one of major blocker that came up was that there were no internal tool, which would be available for everyone and easy to use and take all infrastructure pain points.
In other words, Amazon tried to find a way how to run and deploy applications in a very short time.
And that’s how Amazon Web Services (AWS) was born. First it was as an internal tool, but in August 2006 they decided to make it public, which makes it the first Infrastructure as a Service service.
After that other companies also started to create their own clouds, like Microsoft Azure, Google Cloud, IBM Cloud, Oracle Cloud, Alibaba Cloud, Red Hat Openshift Online. Also new, smaller, companies emerged, like Heroku or Digital Ocean. But none of them, up til now, have such big market share as AWS has.

As all these cloud providers starting to pop up, the decision of which one to choose has started to be more difficult. And I’m not talking about pricing or choosing the best fitting service for organization needs. The problem was with vendor lock.
It occurs when a company, for various reasons (like pricing, location restrictions, feature limitations, performance, etc.), decides to change its cloud provider. It might get quite challenging because organization first needs to learn how to work with new cloud, learn its API and also adopt its automation for deploying applications. Depending on the complexity of an infrastructure this migration may took months, which could cost a lot of money.
So here we finally got to two main problems that we have:
- How to decouple hardware infrastructure from software, so that it can be treated as an abstraction when running applications?
- Is it possible to have a standard approach for working with clouds, no matter of cloud vendor?
To spice it up, during years two major concepts started to gain traction — distributed systems (microservices) and containerization (with Docker in particular).
First concept implies that instead of building single big application, it can be broken into lots of smaller ones which will be responsible for only small part of entire system.
Docker revolutionized a way of working with applications. Containers allows to pack an application with all its dependencies into a small runnable which can be used wherever we want, without much effort of installing additional libraries. And that supports microservice pattern, because each application could be written in a different programming language, giving a flexibility for developers teams to pick a technology that they feel the most comfortable with.
With both of these concepts gaining its momentum it became even more crucial to run an application effortlessly, because instead of one big application sitting on a single server there are now hundreds of smaller microservices running on Docker containers ideally in reliable way. And here Kubernetes is to the rescue.
But before diving into it let me just said, that Kubernetes is not the only, so called container orchestration tool. There are others available, like Docker Swarm, Apache Mesos or Rancher. Some time ago it wasn’t sure which one of them will emerge as a leader technology, but today we can say that Kubernetes become a de facto standard. It becomes even a part of Cloud Native Computing Foundation — organization that is helping to establish standard tooling for software used in a cloud.
Birth of Kubernetes #
Kubernetes was created at Google in 2014. There is no actual date of creation of this project, but usually it’s referred to the first commit on GitHub.

From the beginning it was designed as an open source project which overlaps functionality of Googles’ internal tool called Borg. Like Kubernetes, Borg was created to manage (orchestrate) containerized applications in a time when containers had not yet had so much traction or Docker was not even there. Let’s face it, Google is one of the biggest companies, with huge traffic and needed to have a smart way to manage enormous number of applications.
Based on that experience couple of Google developers decided to create a new open source tool that will do similar job, but in a better, more fresh way.
How it works? #
At this point, I hope you understand what problem Kubernetes tries to solve i.e. it abstracts (virtualize) underlying hardware infrastructure, so that you don’t need to know how it’s build when you deploy an application. It makes easier work for developers and people responsible for infrastructure.
To make it more understandable, let’s consider following scenario.
You would like to create your own Kubernetes cluster. In your basement you’ve found 3, old looking machines:
Raspberry Pi (CPU: 1GB, RAM: 100MB),
an old laptop (CPU: 2GB, RAM: 200MB),
and “ancient” server (CPU: 3GB, RAM: 300MB)
Side note. Please do not pay attention to specific values of CPUs & RAMs, it’s just for presentation purposes 😉.
Once you’ve got them up and running you can install & configure *Kubernetes, *so as a result you should have a hardware infrastructure that has 3 nodes (node, is a separate machine, which can be either physical or virtual).
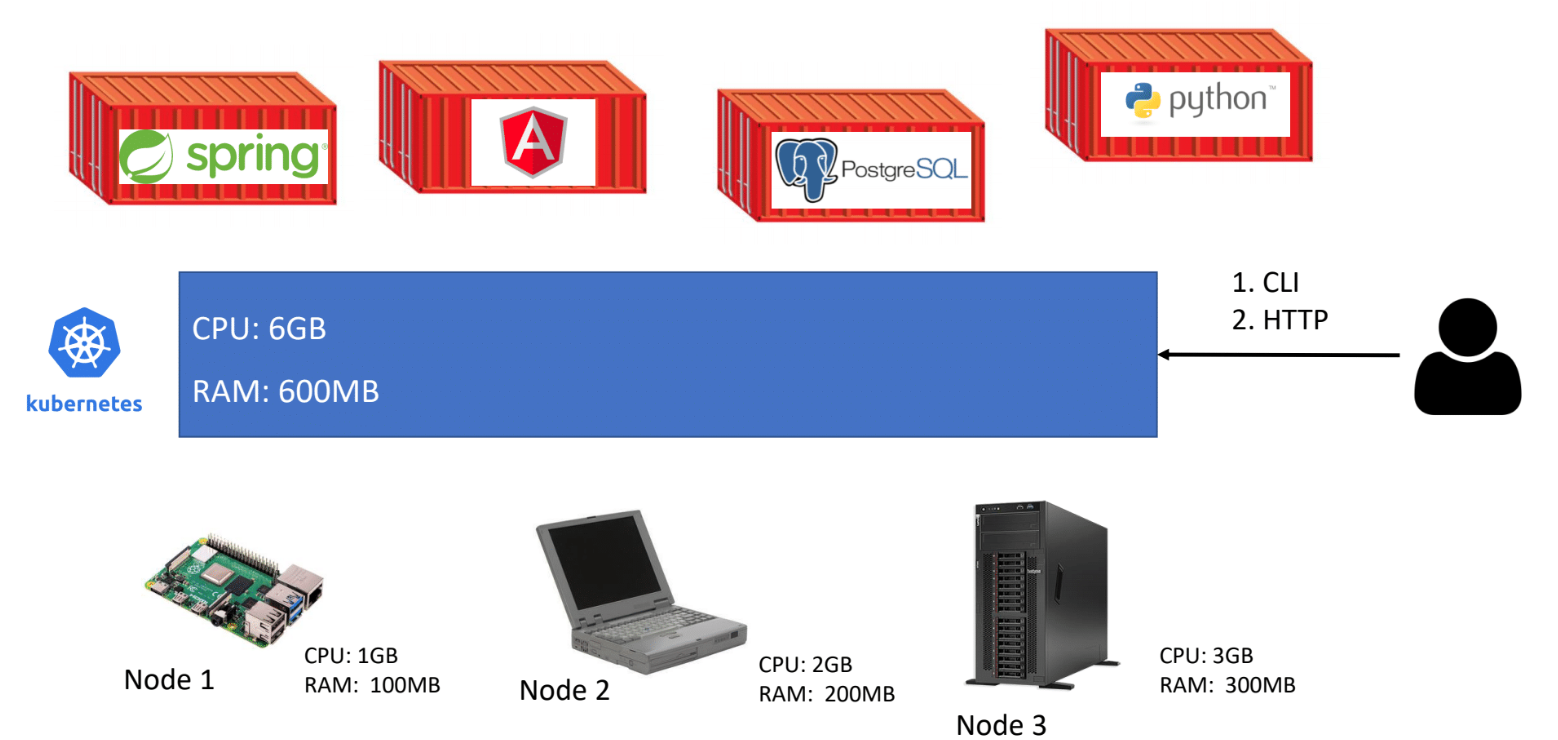
Now if you want to deploy an application to this cluster, you don’t need to think on which machine it should be installed, because K8s (shorter form for Kubernetes) will take care of it. In order to communicate with Kubernetes you can use either command-line tool, kubectl, or HTTP API.
And another cool thing is that all resources of all nodes inside cluster can be treated as pool of them, a sum of all underlying nodes.
Kubernetes architecture #
Looking inside Kubernetes from the architecture point of view we can see two main parts: control plane and worker nodes.

First one is responsible for managing the entire cluster and latter are responsible for hosting applications (containers).
Control plane decides on which worker node run each container, checks health state of a cluster, provides an API to communicate with cluster and many more. If one of the nodes will go down and if some containers were running on that broken machine, it* *will take care of rerunning those applications on other nodes.
Inside control plane we can find several, smaller components:
kube-api-server — it’s responsible for providing an API to a cluster, it provides endpoints, validates requests and delegates them to other components,
kube-scheduler — constantly checks if there are new applications (Pods, to be specific, the smallest objects in K8s, representing applications) and assign them to nodes,
kube-controller-manager — contains a bunch of controllers, which are watching a state of a cluster, checking if a desire state is the same as current state and if not they communicate with kube-api-server to change it; this process is called control loop and it concerns several Kubernetes objects (like nodes, Pod replicas and many more); for each K8s object there is one controller which manages its lifecycle,
etcd — it’s a reliable key-value store database, which stores configuration data for the entire cluster,
cloud controller manager — holds controllers that are specific for a cloud providers, it’s available only when you use at least one cloud service in a cluster.
Also another component, that is not mentioned on a above picture, but is very important, is DNS. It enables applications inside the cluster to be able to communicate with each by specific (human-readable) names, and not IP addresses.
Apart from the control plane each *Kubernetes cluster *can have one or more workorder nodes on which application are running. To integrate them with K8s each one of them has:
kubelet — is responsible of managing Pods inside the node and communicating with control plane (both components talk with each other when a state of a cluster needs to be changed),
kube-proxy — take care of networking inside a cluster, make specific rules etc.
Kubernetes Objects #
In the previous section I’ve mentioned something called Kubernetes Object, so let’s quickly look on what are they.
As mentioned before K8s provides an abstraction of an infrastructure. And to interact with a cluster we need to use some kind of the interface that will represent a state of it. And these are the Kubernetes objects, all of them represent a state of entire system. They are usually defined as a YAML files so that they can be saved under version control system and has an entire system declaratively described, which is very close to Infrastructure as Code approach.
There are several types of objects, but I want to mention only couple of them, which are the most important:
Pods— as mentioned before, Pods are the smallest Kubernetes objects that represents an application. What is worth mentioning, Pods are not containers. They’re wrapper for one or more containers, which contains not only working application but also some metadata.
Deployments — are responsible for a life cycle of Pods. They take care of creating Pods, upgrading and scaling them.
Services — take care of networking tasks, communication between Pods inside a cluster. The reason for that is because Pod’s life is very short. They can be created and killed in a very short time. And every time the IP address can change so other Pods inside cluster would need to constantly update addresses of all depended applications (service discovery). Moreover there could be a case that are more than one instances of the same application inside the cluster — Services take care of load balancing a traffic between those Pods.
Ingress— similar to Services, Ingress is responsible for networking, but on a different level. It’s a gateway to a cluster so that someone/something from external world can enter it based on rules defined in Ingress Controller.
Persistent Volumes — provide an abstract way for data storage, which could be required by Pods (e.g. to save some data permanently or in cache).
ConfigMaps— they holds key-value data that can be injected to Pods, for example as a environment variable, which allows to decouple an application from its configuration.
Apart from standard types of objects Kubernetes offer to create own Custom Resources, which allows to create either new versions of existing objects (with different behaviour) or brand new resource which will cover different aspect. They are widely used in something called Operator pattern and example of such would be a database operator which periodically do backups of databases (more examples of operators can be found on OperatorHub.io). With operators you can easily customize infrastructure to your needs and building the entire ecosystem on top of the Kubernetes.
Other features of Kubernetes #
I hope that now you understand a primary problem that Kubernetes is trying to solve. But this is not everything, there are more aspects of software engineering that it is addressing.
Scalability #
One of the most important features of Kuberentes, that was already partially mentioned, is that it allows to scale number of application instances based on CPU usage (horizontal autoscaling).
This is one of the cloud fundamental concept that depending on how busy an application is (how much of CPU it requires) K8s could decide to run additional instances of the same Pod to prevent low latencies or even crushes.

For example, e-commerce application in summer has rather a low user traffic. Customers prefer spending vacation in great places rather than buying new things. But during the year there are periods (like Black Friday, time before Christmas) when a number of customers using application dramatically increase, which requires more resources on a server side.
In traditional approach to prevent it from happening e-commerce company would need to have a big, expensive server which would be able to handle such peak of a traffic, but for most of the time during a year those resource would not be used (and generate loses for a company).
This is why cloud computing, with Kubernetes, is so popular today. It scales a number of application instances depending on their busyness. You pay to a provider only for how much resources (CPU, RAM, memory) does your application actually require.
High Availability #
When big companies are running their application they want to do that in reliable way. It means that they won’t accept a situation that even for a minute an application could be not working, because they might lose customers and therefore money.
But in real life many bad things could happen. For example, one or more servers (nodes) could went down. Or maybe one or more microservices could went down for whatever reasons. As developers and infrastructure specialists we should make sure that it never happens, but it’s a vain hope.
Luckily Kubernetes has a mechanism to cope with such situation. For example, if an application (Pod) crushes it will try to automatically recreate it. Or if a node go down it will automatically assign all Pods that are running on a crushed node to a new one.

Monitoring & Observability #
As it was mentioned before Kubernetes has an ability to autoscale number of application instances based on CPU usage. It collects metrics from every application about resources usage through the Metrics API, so that it can decide when to increase/decrease number of Pods. Also it can provide current consumption information on a dashboard.

By default Kubernetes provides Metrics Server for providing such metrics, but it can be replaced by custom one. The most popular one is Prometheus.
Another problem of distributed systems is that it is really hard to track full process flow between several applications. In monolithic apps it’s quite simple, there is a one place where process logs could be checked, but in microservice approach you would need to check each application individually.
Therefore, in Kubernetes there are three basic concepts that every application should provide to achieve observability and have full insight about them to a cluster:
metrics — they give information a health status (partially mentioned at the beginning of this section),
logs — represent a descriptive event (usually in full text) inside application written into standard output; all logs from every application can be aggregated to a single place using e.g. Elastic Stack — Elasticsearch, Kibana, Beats and Logstash,
traces —allows to combine multiple events/operations across multiple components, so single trace represents all communication between all components (databases, HTTP requests, etc.); popular tool used for tracing is Jaeger.
Different types of deployment #
One of the biggest challenge in software world is to ship a new version of an application in reliable way. It’s usually a problem of how to quickly roll out new version of it (and if necessary, quickly roll back) and making it almost invisible for the end user.
Some companies are releasing their apps overnight during the weekend. Usually they warn users that for couple hours it won’t be available, so that they are able to do full upgrade. For some use cases this approach is totally fine, but for applications that are served all other the world for a full day, that might be tricky.
In Kubernetes it’s very easy to overcome it by achieving Zero Downtime Deployment. And it’s done by following blue/green deployment pattern .
The concept is quite simple. When we want to release a new version of an app, inside a cluster we deploy a new version alongside with an old one, but at first without routing any traffic to a new instance. Only after making sure that it didn’t break anything user traffic can be routed to a new version.

But there is more. K8s allows to have more complex types of deployments, such as canary deployment or A/B testing. In both of them two versions of a service are deployed alongside.
In a first one traffic is routed only to a very small percentage of a users and then it’s steadily increased if there are no problems.
In A/B testing we want to have two different version of application for a whole time so that we can compare which one performs better (has bigger user traffic, in which one users spend more money, etc.).
Kubernetes Distributions #
If you or a company decides to give Kubernetes a try you might end up with a problem — how to run it? Theoretically it’s possible to clone it’s source code, compile and run it, but it requires so much effort of time and expertise so that you’ll probably decide that K8s is not for you.
Part of a reason is that Kubernetes is highly configurable. Luckily there are people that are real experts in it who provide their pre-configured K8s builds. You can think of them as Linux distributions. All of them were built a little bit different to serve different purpose, for example:
Minikube, Kubernetes in Docker Desktop or Minishift are usually used for local development,
K3s or Microk8s are lightweight production ready distributions,
Canonical Distribution of Kubernetes, OKD or Openshift are heavy guns, production ready Kuberenetes,
Amazon EKS, Google Kubernetes Engine and Azure Kubernetes Service are available only on a particular cloud service.

K8s is not a silver bullet! #
Up till now I was trying to convince you why Kubernetes is great, but now let’s do the opposite. Why Kubernetes is bad?
First of all we need to understand that like every tool K8s was designed to solve problems of a certain type. Yes, it’s very popular nowadays, and yes many companies are either migrating to it or starting new projects using it, but don’t get taken by that. It’s not a silver bullet.
One of a feature of Kuberentes is that it’s highly configurable, it can be adjusted to the own needs, but there is a cost for that. It requires lots of expertise and experience to set up everything correctly, especially for production purposes where security and reliability topics are the most important.
Moreover it may increase an overall complexity of an infrastructure, especially at the beginning when the project is relatively small. Many things could be done simpler (e.g. running all applications on a single Tomcat server). And if there is no plan to launch lots of microservices, maybe just to have couple of bigger apps, it also might be unnecessary to use this tool.
And finally, lots of YAML files 😜 It’s kind of a joke, but I know that some people doesn’t like a fact that Kubernetes requires to create lots and lots of YAML file. To mitagate this problem there are tools like Helm or previously mentioned Kubernetes operator pattern.
New Bright future #
I don’t have a crystal ball to see the future of Kubernetes, but right now we can see several direction towards which it could go.
First of all it enables to build a multicloud or hybrid (both private & public clouds) environments, which gives a flexibility to companies in picking the right cloud solutions. Companies don’t need to be forced to pick only one cloud provider or relay solely on their own data centers. It can be mixed.
Another point is that thanks to extensibility of the Kubernetes (Custom Resources) it allows to build entire ecosystems on top of it. An example of it would be the Knative — an initiative to standardize serverless framework. Also Tekton is build on top of it, which is a cloud native CI/CD tool.
Moreover the community is working on new types of K8s distributions which will be tuned for different purposes, like IoT (lightweight version installed on edge devices) or machine learning. For the latter, there is already a tool called Kubeflow.
And finally Kubernetes has great impact on software development. For instance in Java ecosystem a new type of virtual machine — GraalVM — which makes start up time of an application a way shorter (it’s a specially crucial in serverless workloads). As a result of *GraalVM *new frameworks appeared like Quarkus, Micronaut or there are updates to currently widely used like Spring.
Conclusion #
I hope that after reading all of it you know more about Kubernetes and you understand why it’s so important nowadays. If you like my post or maybe something is still unclear for you, don’t hesitate to write in the comments sections 😉.
References #
- How AWS came to be on techcrunch.com
- From Google to the world: the Kubernetes origin story on cloud.google.com
- Domesticating Kubernetes on blog.quickbird.uk
- Kubernetes Master Components: Etcd, API Server, Controller Manager, and Scheduler on medium.com
- Kubernetes 101: Pods, Nodes, Containers, and Clusterson medium.com
- Demystifying High Availability in Kubernetes Using Kubeadm on medium.com
- Kubernetes Liveness and Readiness Probes: Looking for More Feet on blog.colinbreck.com
- Liveness and Readiness Probes in Spring Boot on www.baeldung.com
- Monitoring and Observability on medium.com
- Kubernetes zero downtime deployment: when theory meets the database on exoscale.com
- Blue/Green Deployments on Kubernetes on ianlewis.org
- How to Choose the Right Kubernetes Distribution on itprotoday.com